Solving little mysteries
Saigon, Viet-Nam!
This was originally written on 3 February 2019.
The next two fields in these old ULP files are titled, simply, “county” and “state.” These seem straightforward enough, but in fact getting these right is key to any project I want to do. Any hypotheses about where ULPs happened historically, and whether and how that changed over time, can only be tested if the geographic information is good. I need to lay some foundations for these to work.
Consider the relevant page from the code book:

Notice a few things here. No text is recorded in this file, remember; everything’s a code whose key is external to the file. Here, the codebook just points us to another codebook. Counties and states are recorded using a numerical code maintained by the General Services Administration’s Office of Finance. We have an example: Erie County, Ohio is encoded as 04334, i.e., Ohio is 34, and Erie County within Ohio is 043. To Google!
My first guess is that these are, at root, FIPS codes, part of the Federal Information Processing System. There are standardized FIPS-2 codes for the states, and FIPS-5 codes for the counties. (The first two digits of the latter are the state codes.) I’ve used these codes more times than I care to count, and have some Stata scripts that I use to encode such variables and give them nice value labels. I’m trying to do these things in R, though, and so I want to rebuild material like that.
A quick search of the General Service Administration’s site reveals that, yes, the Geographic Location Codes are based on the FIPS, and they have available for download an Excel file filled with cities and their relevant geographic codes:

The problem here is that I only need unique county codes. This file has unique city codes, which means it repeats many of the counties many times. It’s okay, though. This is why the Good Lord gave us Emacs.
This is not the place to sing the praises of Emacs. Suffice it to say that, if you scale no other learning curve in graduate school, you should just learn how to use Emacs. (This is just my opinion, but I am right.) Any number of bonkers tricks are possible with Emacs, but one of the ones I use most often is manipulation of structured text like this, through the use of regular-expression replacements and keyboard macros.
I wrote up a detailed example of how you might transform that Excel file into something like this using Emacs…

…but I deleted all of it, because it felt more like I was showing off than like I was imparting useful information. In point of fact, there are many, many good tutorials on using Emacs to be found online and indeed within Emacs itself. And, to be fair, a lot of people who have no fear of complicated text manipulation nonetheless despise it. (I’m looking at you, Vi users.) I think it’s the best thing for a lot of our work, but the larger point is that the power of a good text editor is not to be ignored.
And in any case, this post is supposed to be about solving little mysteries. Let’s get to that.
…In which everything goes wrong
Notice that that codebook page doesn’t specify which edition of the GSA’s geographic location codes it’s using. I figured that this file was created in the 1980s and covers 1963 through 1976, so I could use the 1976 edition of the codes. A quick check of the 1972 edition showed very little changes, and indeed the codings of the states and several prominent counties in the 1976 edition were ones that I recognize from the current editions. (There’s no state with the code 03 for example; we go from Alaska at 02 to Arizona at 04.) Based on these correspondences, I figured it would be safe to build county codes by transforming that Excel file from the GSA.
So, I did that:


Notice that the text names that I’m giving those counties–the labels that will appear once the factor variables are properly encoded–also have the two-letter state in them. This is important. Tons of states have Washington or Jefferson Counties (And Wyoming Counties! It’s a river in Pennsylvania, people!). If you don’t distinguish the state in the county names, the best-case scenario is that your function will fail because the factors are not uniquely identified. The worst-case scenario is that it doesn’t fail, and now you have multiple factor variables with the same label. This defeats the purpose of having labels.
So, I wrote up some long functions that would define factor variables for counties and states, with all the relevant codes and labels in them. I wrote these functions in a separate file, with the idea that I will re-use these a lot. That’s a good practice that’s almost as old as programming itself. Yet when I started tabulating the encoded data, I almost immediately saw problems.
I encoded the states, then started trying to check that the encoding worked. For example, I thought I’d make sure that counties were mapping uniquely to states. But that didn’t seem to be happening:
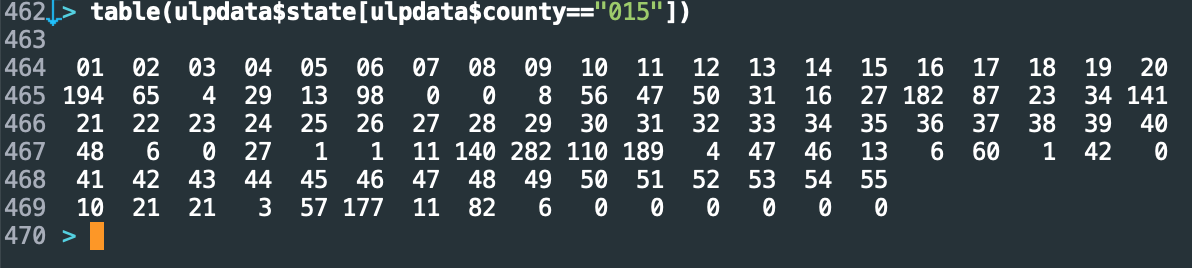
It appeared that the county designation 015 was spread across almost all states. This happened with others as well. For several minutes, I despaired, thinking that this project might be dead in the water. If the geographic location data wasn’t any good, there wasn’t much point continuing.
And then I calmed down
You might already have seen the problem here. When I defined the county-encoding function, I was careful to use the five-digit codes. The whole reason for doing so is because 015 shows up in many states. Yet when I tabulated the counts of that code across states, I just used the three-digit code, which of course repeats!
I mention all of this because this is a blog about doing a research project. And, for me at least, one unavoidable aspect of doing research is making mistakes and immediately thinking that
The data, and the whole project, might be trash from a nightmare realm
I am an idiot who doesn’t deserve to live, much less do research
The first is almost never true, and the second never is. Yet I find it distressingly easy to read too much into things like this and get discouraged. You might, too. So it’s worth mentioning.
That said, I still had a problem. When I tabulated the states, the counts looked all wrong:
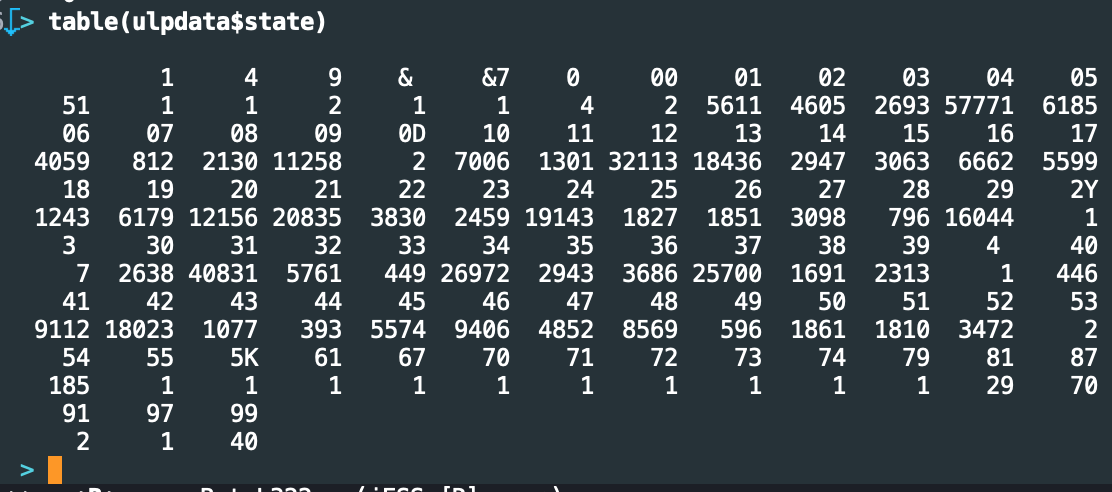
A thing about the output of R’s table() function: it lists values above then counts below, left to right. This is telling us for example that 1 record has the state recorded as &7, 5,611 have it recorded as 01, and so on. What I want you to focus on are the counts for 03 and 04. I mentioned above that the FIPS-2 doesn’t have a label for 03; so why are there 2,693 records with it? Furthermore, 04 is Arizona, while 06 is California. Yet here, 06 only has 4,059 records, while 04 has fully 57,771! That makes no sense.
Further inspection of these counts seemed to point to several large states being one or two positions off from where they should be. Notice the bunching around 37, which screams “New York”; but New York should be 36. But then 42, which encodes Pennsylvania, looks to be the right size…
Eventually, I surmised that the NLRB had kept using a much older edition of the GSA Geographic Locator Codes, long after revisions had come out. I surmised this because I’ve seen it in other federal datasets. The EEOC, for example, used 1987 SIC codes to track industries until the early 2000s, even though Commerce had nominally retired the SIC and switched to the NAICS codes in 1997. For the record, this isn’t a story of government sloth. Historical comparability across time periods is a big deal in datasets like these, and should be weighed carefully against updates to the coding scheme.
More Googling led me to a scanned copy of a 1969 edition of the GSA’s Geographical Location Codes, provided by the University of Michgan to someone. Before I go on, let’s just pause to admire this gem of a cover:

How old-school can you get? We’ve got magnetic tape; we’ve got punched cards; Hell, their example of a foreign-yet-familiar place is “Saigon, Viet-Nam!”
I love the smell of old documents in the morning. It smells like comprehension.
Inside was the key I needed:

Bingo. In the 1969 and earlier editions, California was coded 03, Pennsylvania was actually coded 37–but Texas was 42, which makes sense. Dig how Alaska was 50 and Hawai’i was 51. This strongly suggests that this edition included incremental changes from some point in the 1950s, before either became a state.
Let’s recap
This whole post is about the challenges of getting two simple variables coded. Nor are the codings themselves complicated. All I’m trying to do is apply “standardized” government labels to places. Yet we’ve seen code books referencing other code books, and we’ve seen how changes across time and place can complicate the application of even simple schemes.
We’ve also seen how important it can be to run multiple “sanity checks” on data as you build it. My encoding function ran without errors, after all, yet it produced semantic gibberish. Good exploratory data analysis involves repeatedly testing assertions about what should hold in the data, given your prior assumptions and what you’ve done to transform the data. Better to do this now than to get all the way to the analysis (or worse!) and have to backtrack dozens of steps.
Nor is any of this wasted time, even if you don’t find some confusing error that threatens to throw you into the slough of despair. Rooting around in your data, at this low level, is how you develop a sense of what’s in it. That intuition will be leveraged later on.
On yak shaving
You don’t think you’ve done it, but you have; you don’t think you need to do it, but you do.
This was originally written on 27 January 2019.
It is hard to do quantitative social science without picking up some of the habits of computer science. Most of these are technical, but sometimes you imbibe a bit of the culture as well. One cultural artifact that I picked up while a graduate student at MIT was the concept of “yak shaving.” I’ll quote a definition:
You have probably noticed how the tiniest Java programming project, or home improvement project often grows seemingly without bound. You start to do something very simple. You need a tool to do that. You notice the tool needs to be tuned a bit to do the job properly. So you set out to sharpen the tool. To do that, you need to read some documentation. In the process, you notice the documentation is obsolete. So you set out to update the documentation… This chain goes on and on. Eventually you can unwind your to-do stack.
Ultimately, there’s a Ren and Stimpy episode whence the term comes. But this, reader, is yak shaving: doing the thing you need to do to do thing you need to do to do the thing.
If a project needs any new software, then it will involve yak shaving. The sign of an experienced social scientist is not that they do less yak shaving. It is that they learn to budget time for yak shaving. You cannot know the length of all yaks' hair in advance, but you know there lurks a shaggy bastard among them.
I have decided to analyze my Unfair Labor Practice data (see the previous post) using R, because R is what The Kids Today use. I’ve used some version of Stata since 2000, and I’m both good and fast in it. Yet I can feel the gap opening up between Stata’s metaphor of doing quantitative social science and the rest of the world. Every time I have to work with many small (or large!) data files, I feel the constraints of Stata’s “one data set in memory” architecture binding me. I also like to work with graduate students and younger faculty, and these days, no one learns Stata in their methods classes. I’ve always rolled my eyes at the senior faculty who force their students to learn SAS or (shudder) SPSS because they can’t be bothered to adapt, and I don’t want to join their ranks. So, R.
Thus, new software. Thus, yak shaving.
Yesterday I sat down planning to read the fixed-width text files I downloaded from CISER into some sort of database, then clean it up in R. I quickly realized that there just wasn’t enough data here to worry much about a database as such. Uncompressed, this dataset comprises two files, each about 35 megabytes. It would be simpler just to read things directly into R.
The first digression
To this point, I’d saved the archives from CISER in my Downloads folder. This wouldn’t work going forward; any project requires more organization so you can remember how the pieces fit together when you go away and come back to it.
In principle, you can create a folder named “Project” and save everything inside it. I did this for my first couple projects. It sort of worked, but only because I have a good memory. As soon as I started working with co-authors, I discovered all the ways this was insufficient. I therefore started making project directories that have a structure like this one:

Here, “canonical” holds primary data. Is it a file that you cannot re-create using other files in the project? Then it goes in canonical. By contrast, any data files that I create go in “data,” and the code that generates them goes in “scripts.” I put any codebooks, manuals, or the like in “documentation,” and any articles or book chapters that inform the substantive research question (as distinct from the data-creation and -analysis processes) in “literature.” The output of the project winds up in “drafts,” “figures,” “tables,” and “presentations,” in ways that are probably self-explanatory.
This whole directory lives on Dropbox. Here, the data are public, and so there’s no privacy concern with posting things this way. My experience over the last eight years has been that Dropbox is the easiest way for me to share files with co-authors and keep everything synced. Before this, I used Subversion, but found that some co-authors never really cottoned to version control. For similar reasons, I’ve been slow to move things into Git repositories. Maybe some day. The key point is that, this way, the entire project lives somewhere that is shared, automatically synced, and protected with version control.
Thus the very first bit of yak shaving: organize the original files, such that the text files are in canonical and the codebooks are in documentation.
Reading time
Reading fixed-width data into R is easy enough; you can use read.fwf() to do it. That command requires you to specify the widths of each element, that is, their start and end positions in the original 80-character record. This is where the codebook becomes important:

The codebook tells me, for example, that element 15 (the count of charges in the situation) is 3 characters wide (fields 41-43), that elements 16 is one character wide, and so on. I thus tried doing just that, and ran into problems:

The read.fwf() command is expecting simple ASCII or UTF-8 unicode in the text file. Fancy characters and multibyte strings are a problem because they violate the one-character, one-field mapping that a fixed-width file is supposed to respect. You see this sometimes: somewhere along the way, there was a mistake such that characters were written wrong at the bit level. This isn’t something that read.fwf() knows how to handle, and it dies. The solution is to inspect the file for non-ASCII characters, try to strip them out and replace them with whatever is supposed to be there, and move on.
The standard tool for this is grep, which if you haven’t used it means “Get Regular Expression and Print.” (If you’re doing quantitative social science and haven’t heard of grep, it’s time to stop and re-examine your priorities.) I don’t do this often, but I know that there’s a pretty standard way to search for non-ASCII characters. Some Googling pulls up the right pattern; I try it, and no dice:

It seems that the version of grep that comes standard on the Mac doesn’t recognize the -P flag! Some more Googling reveals that, as of Mountain Lion, OSX uses BSD grep rather than GNU grep, and the former doesn’t support “Perl compatible regular expressions,” which is what I specified. All is not lost, though, because there’s a package I can install with the remarkable Homebrew (If you use a Mac and do not use Homebrew, again with the priorities) called “pcre” and which has inter alia a command called pcregrep which, well, you can guess from the name.
So, I type brew install pcre. No dice again:

Xcode is out of date! If you do any sort of programming or even package management on a Mac, you know what Xcode is: the suite of developer tools that for some reason aren’t installed by default. I have them on this machine, but I haven’t updated them recently, and Homebrew has determined that some of pcre’s dependencies require a newer version. So, I start updating Xcode…which usually takes a little while.
Down the rabbit hole
This is a good time to recap. Right now,
- I am updating Xcode…
- …so I can install the pcre package…
- …so I can find non-ASCII characters in
unf.labproc.c6376… - …so I can bring the file into R with
read.fwf().
This is classic yak shaving. Frankly, I’m a little nervous that I’m going to have to update my operating system next…but no, Xcode eventually updates, and I start climbing back up the chain. Eventually I can run pcregrep and get real results:

This is telling us that, on the 257,194th line of this file (which has about 440,000 lines), There is a non-ASCII character just before the characters “806.” This is telling, because if you go back to the original error message, it said that there was an invalid multibyte string at '<ba>806<39> \'. It looks like this might be our culprit. Furthermore, when I open the file in Emacs and go to line 257194, I see a superscript “o” in that position. My best guess (trust me?) is that this is supposed to be a zero.
I change it, save the file, and run pcregrep again. This time it exits without reporting any hits. It seems we’ve found the source of the hiccups…
…until the next error. This one turns out to involve a lot of Googling, but little actual yak shaving. The file includes #s, which are a comment character in R. You have to tell read.fwf() that the comment character is something else–I chose nothing–so it will ignore these. With that change, I can read in the file at last!
And so it goes
As it turned out, I wasn’t done shaving yaks for the day. A lot of the data are stored as factor variables. I wanted to use the recode() command to clean these up. That command is in R’s “car” package, and to install that I had to update my version of R. Then, when I tried to install the all-important “tidyverse” package, I found that a chain of dependencies did not resolve because, ultimately, the “xml2” package relied upon the libxml-2.0 library, which isn’t on the Mac by default…
…You get the idea. I worked on all of this for about five hours, off and on, yesterday. By the time I went to bed, I’d read in the first of the two ULP files and cleaned up 4 of its 40 variables. Some of the intervening time was spent learning the ins and outs of working with factor variables, date variables, and string functions in R, but the majority of the time was spent yak shaving.
I do not take this as a sign of incompetence. As I said at the start, experience doesn’t mean you do less yak shaving, it means you budget time for this. I know that the first several days on this project will have this feel. Could I do all of this in Stata, and already be done with this stage? Absolutely–but then I wouldn’t have learned anything about R, and I’d still have to do all of this if I were to try it in the future.
This is a trade-off in research that we all become familiar with. When does it make sense to invest the time to learn new tools? When is the productivity lost now outweighed by gains in the future? Many people, myself included, have to be careful about this, because “tooling up” can become a form of procrastination. The worst vices are the ones that can look like virtues. Here, I’ve specifically decided that this project will happen in my spare time, and that learning new systems is as big a part of it as the final result, so I don’t mind how that spare time is spent. But striking the right balance between tooling up and getting things done is one of the most important things one must do in a self-directed career like academia.
A blast from my past
If you keep searching for ten years…
This was originally written on 21 January 2019.
A whole lotta context
In 2009, I attended a talk by Bruce Western about the collapse of trade-union norms in the United States. He and Jake Rosenfeld had this paper where they analyzed the effect of trade-union membership on wage dispersion in various areas and times. They argued that “unions helped institutionalize norms of equity, reducing the dispersion of nonunion wages in highly unionized regions and industries.” The fall of the house of labor, in turn, explained a non-trivial share of the growth in U.S. wage inequality in recent decades.
It’s a neat paper-–I mean, it did well-–but I’ve never been OK with their argument that we could read a story of changing social norms into these data. Sociologists like the idea that many of our decisions are embedded in a moral economy, and that we rule out some actions not through any cost-benefit analysis but because we have been socialized to think that those actions are categorically wrong. I buy this idea, but it’s miserably hard to show. Never mind that we cannot put a probe in people’s heads and observe norm compliance. Many are the alternative reasons we could observe new patterns of behavior that have nothing to do with shifting norms. Here Randall Collins deserves a shout-out:
Of course, one may rescue the norms or rules as nonverbalizable or unconscious patterns which people manifest in their behavior. But such “norms” are simply observer’s constructs. It is a common, but erroneous, sleight-of-hand then to assume that the actors also know and orient their behavior to these “rules.” The reason that normative sociologies have made so little progress in the past half century [prior to 1981, that is] is that they assume that a description of behavior is an explanation of it, whereas in fact the explanatory mechanism is still to be found. It is because of the potential for this kind of abuse that I believe that the terminology of norms ought to be dropped from sociological theory.
Gauntlet tossed down, Mr. Collins! I don’t think I’m ready to bin the term, but clearly there’s a bar we have to clear.
I mention all of this because the talk got me thinking. Changes in pay setting, by themselves, are interesting but hard to assert as changes in norms. What would be easier? The idea I had, sitting in that talk, was that you would want to look at something that had been widely accepted but then became censured or illegal; or, conversely, something that had once been censured or illegal that then became, well, normal.
With labor unions, we have something like that. The Wagner Act, which governs union formation in US workplaces, specifies various Unfair Labor Practices. These are things employers (and, later, unions) are prohibited from doing, under pain of legal penalties. They include intimidating workers during union-organizing campaigns, firing workers for union-related activity, and refusing to bargain in good faith with workers' legally certified representatives. For decades after the Wagner Act was passed in 1935, charges of ULPs were relatively rare. Starting in the 1970s, though, they started to take off.
Throughout the 1980s, people interested in industrial relations remarked on the increase in nominally illegal employer resistance to unions. The rate of ULP charges relative to union activity probably peaked in the 1990s. After that, they began a slight decline, but that’s relevant. By that point, “illegal” employer resistance had become so common, and attempts to sanction it so unsuccessful, that many union organizers seemed to abandon the formal complaint channel. Said differently, something that had once been censured or illegal had become, well, normal.
A false start
I left that talk with a research idea. Wouldn’t it be neat to study the spread of ULP charges? No one had really done this before. I could imagine different predictions: that these had been more common in less profitable, more competitive industries, but had spread into the economic “core,” or that they had spread from more anti-union states and regions to more union-friendly ones. I had been working on labor-union representation-election data for my dissertation (my first “real” academic research was on ULPs during election campaigns), and so understood this stuff well. I was also finishing up my PhD at MIT and soon off to Stanford to start as an Assistant Professor, so this seemed like a fun post-dissertation project.
I almost immediately ran into problems. I had forged a good relationship with the AFL-CIO’s research office during graduate school, and had strip-mined their computers for archival data that no one else seemed to still have. I had representation-election data, for example, going back to the mid-1960s. Yet when I pored over their old files, I found that their micro-data on ULP charges only went back to 1990. This was way too late–-all of the action would be in the 1970s and 1980s. Worse, the AFL-CIO’s data was better than the primary source, the National Labor Relations Board. A very friendly lawyer at the NLRB’s San Francisco offices told me that they didn’t keep any of their historical micro-data–-“But you can find any information you need in the tables of our annual reports!”
If you do quantitative research, you’ll recognize how dispiriting that remark is. I could get counts of charges by region, and I could get counts of charges by industry, but I couldn’t find out which industries were in which regions, and so on. I spent a while digitizing information from those annual reports (for which thanks to Amanda Sharkey, whom I met as an RA at this point), but it was a lost cause. I set the idea aside.
A new hope
There the story seemed to end. But then we cut to this past November, 2018. I still do pro bono data analysis for the AFL-CIO from time to time. This fall, I was one of several people working on briefing papers for their Future of Work Commission. Larry Mishels of the Economic Policy Institute wrote me. For his own briefing paper, he was running some simulations, and he needed values for some of his parameters. What was the win rate in union representation elections in, say, 1987? I’m one of the few people who is conversant with the election data, so Larry and I got to talking.
One of the things Larry needed to know was the size of the work groups involved in each election. In the NLRB’s Case Handling Information Processing System (CHIPS), which they used from roughly 1984 to 1999, there is a field in each record for the unit size. It isn’t a real number, though; it’s a categorical variable. This almost certainly corresponded to a coding scheme: 0 for 1-9, 1 for 10-19, 2 for 20-49, and so on. Where there’s a coding scheme, there must (or at least should!) be a codebook. But where?
I went online. Some searching directed me to Google Books, which hadn’t really existed back in 2009, and there I found an obscure volume by Gordon Law detailing sources of information about the NLRB. Eventually I was looking at this screenshot:

Let me highlight a bit:
Data files were also produced covering elections (1972-1987), representation cases closed (1964-1986), and unfair labor practices (1963-1986), although these are not available from the National Archives and Records Administration. One copy of these earlier files is held by the Data Archive at the Cornell Institute for Social and Economic Research.
Reader, my heart skipped a beat when I saw that. At some point in the late 1980s, someone had made a data-dump of the NLRB’s ULP micro-data, and it might still exist!
I hied to CISER’s website, and sure enough, they seemed to have the goods. I downloaded a series of files, unzipped one, and ran head to see what was in them:

That might look like gibberish. The key thing, though, is that each of the lines that ends in a backslash is exactly 80 characters long. Back in the day, a standard IBM punched card held 80 characters' worth of data. (This is why standard terminals are also 80 characters wide.) All signs point to these being the original records–and CISER had a code book, too.
Suddenly, nearly a decade after I set this project aside, it seemed like I could actually do it.
Why I am writing this
If you’ve read this far, congratulations. Why so many words about this?
This project isn’t core to my research program. Heck, I’m knocking on tenure these days, and I have more than enough to keep me busy. I have a new website, though, and it would be nice to have content for a blog. What’s more, there are a lot of ways in which my research habits have ossified. I really should be using R and relational databases these days, but I still fall back on Stata for most tasks. What I need is a real project that I can use to retool, but a project that isn’t so large or complicated that re-learning data management and exploratory data analysis while working on it would be infeasible. Something like, say, modeling the spread of unfair labor practice charges?
I therefore thought I’d do some radically open science: I’d detail this project here on this blog. I do this in part so that I’ll have a record to show students of how research in our field actually happens. And along the way, perhaps I’ll have some fancy graphics to show you.
I do not expect posts to be that frequent; this really isn’t my main project. But it’ll be nice to have something to unwind with. So, forward!
First post
Hello, World.
This post was originally written on 20 January 2019.
“Hello World” messages are a cliché, but here goes. I’ve had a web presence of some sort since 1996, but done my best not to learn much actual web design. Thus my typical web page has been hosted on a university server where I’ve had an account–real “www.university.edu/~user" sort of stuff. Since I haven’t focused on web development since before CSS became a standard, this did not push me too hard.
In recent years, this has grown insufficient. I needed a place to put data and descriptions of projects, above and beyond a GitHub account. More importantly, I find myself repeating certain points to people in my professional life, and it would be useful to write up such ideas so I can point people to them.
Practicing my writing in a semi-public forum cannot hurt either…
So, a revamped web site. As the appearance suggests, I am disinclined to expand too far beyond my roots messing with Notepad and Netscape Navigator 1.1. Though we’ve come a long way in terms of the back-end. On that note, I owe a thanks to Yihui Xie, who wrote a simple-enough Hugo theme that even I could reverse-engineer the code into something I could understand.
Update 29 June 2021: I’ve moved to Squarespace because reasons. Re-uploading an old post about moving to GoDaddy and Hugo on your shiny new web site just screams “completionist”…